
🙆♂️ DB와 연동
파이썬은 만능입니다. pymongo 라이브러리를 활용하면 됩니다.

저는 Anaconda의 Jupyter Notebook을 사용하기 때문에 간단하게 설치했습니다.
#requests import
import requests
#bs4 import
from bs4 import BeautifulSoup
def notices(targetUrl,page_index):
#targetURL
base_url=targetUrl
#post param
post_params = {'page':page_index}
#응답 값은 response에
res = requests.post(base_url,data=post_params)
#응답에 실패하면
if res.status_code != 200:
#그냥 print
print("Can't")
#응답에 성공하면
else:
#결과 저장 리스트
results=[]
#BeautifulSoup 생성해서 soup으로 사용
soup=BeautifulSoup(res.text,"html.parser")
#td태그들 값을 저장(find_all)
tds = soup.find_all('td',class_="_artclTdTitle")
for td in tds:
#td 중 a태그 추출
anchors = td.find_all('a')
#추출한 a태그 정제
for anchor in anchors:
link = f"https://community.bu.ac.kr{anchor['href']}"
#a태그 속 title이 저장된 span태그 find하기
title = anchor.find('span')
rst={
'title':title.string,
'link':link
}
results.append(rst)
return results#requests import
import requests
#bs4 import
from bs4 import BeautifulSoup
from scrapModule.scrap import notices
noticeList = []
i=1
while 1:
notice = notices("https://community.bu.ac.kr/info/1787/subview.do",i)
if notice != []:
noticeList.append(notice)
i+=1
else:
break
print(noticeList)
현재까지의 코드는 이렇습니다.
완벽한 코드는 아니고 여기서 이 데이터들을 DB에 저장하는 연습을 해보겠습니다.
from pymongo import MongoClient
client = MongoClient('연결할 URL')
db = client.데이터베이스명간단한 코드는 위와 같습니다.
연결할 URL을 얻어오기 위해서는 다시 MongoDB 사이트로 가야합니다.

먼저 만들었던 MongoDB에서 DataBase탭에서 Connect를 누르면 밑에 처럼이 나옵니다.

Connect your application을 선택해서
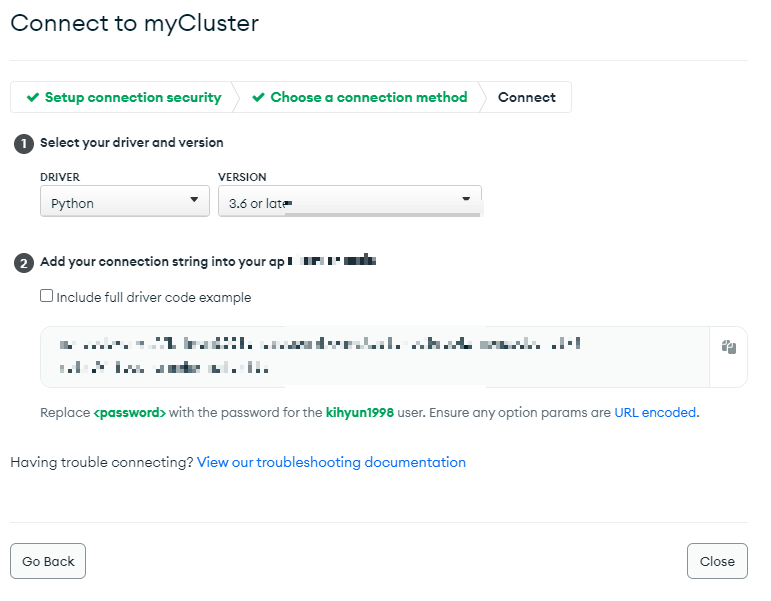
Driver를 Python으로 선택하고 Version은 3.6 이상으로 선택하면 링크가 나옵니다.
저 링크를 복사해가지구

이런식으로 넣는데 <password> 부분에 설정한 DB 비밀번호를 넣어주시면 됩니다.
pymongo 기능으로는 입력, 탐색, 변경, 삭제를 할 수 있습니다.
지금은 입력만 해보겠습니다.
pymongo가 에러가 나신다면 이 게시물에 해결법을 적어놨습니다.
이제 코드를 변경해서
#requests import
import requests
#bs4 import
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('연결 URL')
db = client.DB명
def notices(targetUrl,page_index):
check=0
#targetURL
base_url=targetUrl
#post param
post_params = {'page':page_index}
#응답 값은 response에
res = requests.post(base_url,data=post_params)
#응답에 실패하면
if res.status_code != 200:
#그냥 print
print("Can't")
#응답에 성공하면
else:
#BeautifulSoup 생성해서 soup으로 사용
soup=BeautifulSoup(res.text,"html.parser")
#td태그들 값을 저장(find_all)
tds = soup.find_all('td',class_="_artclTdTitle")
for td in tds:
#td 중 a태그 추출
anchors = td.find_all('a')
#추출한 a태그 정제
for anchor in anchors:
link = f"https://community.bu.ac.kr{anchor['href']}"
#a태그 속 title이 저장된 span태그 find하기
title = anchor.find('span')
rst={
'title':title.string,
'link':link
}
print(rst)
check=1
return check함수 코드는 위와 같고
#requests import
import requests
#bs4 import
from bs4 import BeautifulSoup
from scrapModule.scrap import notices
from pymongo import MongoClient
client = MongoClient('연결된 URL')
db = client.DB명
i=1
while 1:
check = notices("https://community.bu.ac.kr/info/1787/subview.do",i)
if check == 1:
i+=1
else:
break크롤링 코드는 이렇습니다.
실험적으로 실행해보면

원하는 방식으로 출력됩니다. 이제 print한 부분에 다른 코드를 넣으면 됩니다.
db.test1.insert_one(rst)insert_one 함수를 써주면 되는데
print(rst)부분을 위처럼 바꿔주면 됩니다.
db는 위에서 설정한 변수고 test1은 collection 명이라고 원하는 collection 명을 입력해주면 됩니다.
생성된 collection이 없다면 자동 생성됩니다.
크롤링 파일을 실행하고 MongoDB로 돌아와서

Browse Collections를 클릭하고 보면

잘 저장된 모습을 볼 수 있습니다.
'웹 개발 > 프로젝트' 카테고리의 다른 글
| [웹 크롤링 프로젝트] 05. Fast API 도커 배포 - 1 (FastAPI 시작하기 수정) (1) | 2022.11.25 |
|---|---|
| [웹 크롤링 프로젝트] 04. AWS EC2 서버 사용하기 (0) | 2022.11.15 |
| [웹 크롤링 프로젝트] 03. Fast API 시작하기 (0) | 2022.11.15 |
| [웹 크롤링 프로젝트] 03. Node Express 서버 구축 및 DB 연동 (0) | 2022.10.19 |
| [웹 크롤링 프로젝트] 01. MongoDB 사용법 (1) | 2022.09.30 |