
🙆♂️개념
웹 스크래핑을 위해서 beutifulsoup4를 설치해서 사용해야 합니다.
https://pypi.org/project/beautifulsoup4/
beautifulsoup4
Screen-scraping library
pypi.org
해당 라이브러리는 위에서 설명해줍니다.
저는 Anaconda의 Jupyter-notebook을 사용하기 때문에 설치되어 있답니다.
이 때 주의할 점이 웹 스크래핑을 할 때 상업적으로 이용할 목적이라면 아주아주 조심해야 합니다.
이용약관과 법을 잘 찾아서 해보시구 저는 비 상업적 목적으로 진행할 예정입니다.
🙋♂️ 학사 공지사항 가져오기
from requests import get
base_url="https://community.bu.ac.kr/info/1787/subview.do"
response = get(f"{base_url}")
print(response.text)https://community.bu.ac.kr/info/1787/subview.do
학사공지
community.bu.ac.kr:443
이 곳에서 공지들을 긁어 오기 위해서 HTML을 긁어보면

다양한 HTML 속에서 첫 번째 게시글이
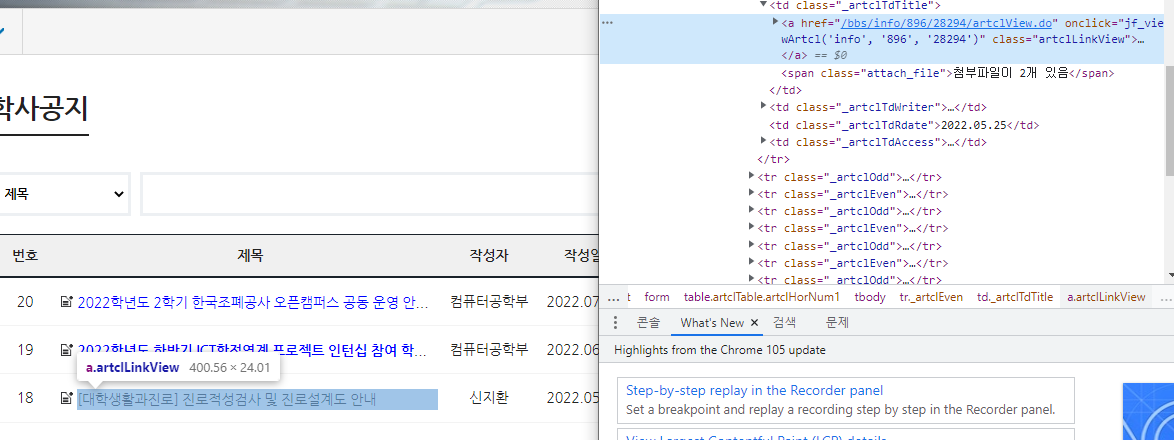
18번 글이 28294번 글인데

jupyter의 결과를 보면 28294번이 담겨 있는 태그를 발견할 수 있습니다.
하지만 너무 길어서 이게 좋지 않기 때문에 beutifulSoup4를 이용해서 더 간단하게 정리해보겠습니다.
from requests import get
from bs4 import BeautifulSoup
base_url="https://community.bu.ac.kr/info/1787/subview.do"
response = get(f"{base_url}")
if response.status_code != 200:
print("Can't")
else:
soup=BeautifulSoup(response.text,"html.parser")
print(soup.find_all('a'))
from bs4 import BeautifulSoup위의 코드를 통해서 BeutifulSoup4를 가져와서 BeurifulSoup라는 이름으로 사용하도록 선언했습니다.
그리고 밑에 코드를 보면 if문을 통해서 서버 통신이 됐을 때 즉 status_code가 200으로 나왔다면
reponse.text를 가져오고 그 중 a태그만을 출력하도록 했습니다.

결과를 보면 이렇게 a태그만 잘 정리돼서 나오는 모습입니다.
더 정확하게 확인해보겠습니다.

위 처럼 td태그에 class 이름을 _artclTdTitle로 갖는 태그들을 찾아보겠습니다.
else:
soup=BeautifulSoup(response.text,"html.parser")
print(soup.find_all('td',class_="_artclTdTitle"))else 부분의 코드를 이렇게 수정한다면

이렇게 스크랩핑이 잘 됐습니다.
이런식으로 진행하려 했으나... URL만으로는 이동이 어려워서 Sellenium도 같이 사용해야 할 것 같네요.
'웹 개발 > 크롤링' 카테고리의 다른 글
| [웹크롤링] post방식 requset 웹 크롤링하기 (1) | 2022.09.30 |
|---|---|
| [웹크롤링] 04. beautifulSoup 좀더 자세히 (0) | 2022.09.21 |
| [웹크롤링] 02. requests 라이브러리 (0) | 2022.09.15 |
| [웹크롤링] 01. URL 포맷하기 (0) | 2022.09.15 |